#kubernetes testing
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Mobile US users spent an average of 115.8 minutes on Tumblr app monthly.
Text
Tips to Boost Release Confidence in Kubernetes
Software development takes a lot of focus and practice, and many newcomers find the thought of releasing a product into the world a bit daunting. All kinds of worries and fears can crop up before release, and even when unfounded, doubt can make it difficult to pull the trigger.
If you’re using a solution like Kubernetes software to develop and release your next project, below are some tips to boost your confidence and get your product released for the world to enjoy:
Work With a Mentor
Having a mentor on your side can be a big confidence booster when it comes to Kubernetes software. Mentors provide not only guidance and advice, but they can also boost your confidence by sharing stories of their own trials. Finding a mentor who specializes in Kubernetes is ideal if this is the container orchestration system you’re working with, but a mentor with experience in any type of software development product release can be beneficial.
Take a Moment Away From Your Project
In any type of intensive development project, it can be easy to lose sight of the bigger picture. Many developers find themselves working longer hours as the release of a product grows near, and this can contribute to stress, worry and doubt.
When possible, take some time to step away from your work for a bit. If you can put your project down for a few days to get your mind off of things, this will provide you with some time to relax and come back to your project with a fresh set of eyes and a clear mind.
Ask for a Review
You can also ask trusted friends and colleagues to review your work before release. This may not be a full-on bug hunt, but it can help you have confidence that the main parameters are working fine and that no glaring issues exist. You can also ask for general feedback, but be careful not to let the opinions of others sway you from your overall mission of developing a stellar product that fulfills your vision.
Read a similar article about Kubernetes dev environments here at this page.
0 notes
Text



A Kubernetes CI/CD (Continuous Integration/Continuous Delivery) pipeline is a powerful tool for efficiently deploying and managing applications in Kubernetes clusters.
It is a workflow process that automates the building, testing, and deployment of containerized applications in Kubernetes environments.
Efficiently Deploy and Manage Applications with Kubernetes CI/CD Pipeline - A Comprehensive Overview.
2 notes
·
View notes
Text
A Comprehensive Guide to Building Microservices with Node.js
Introduction:The microservices architecture has become a popular approach for developing scalable and maintainable applications. Unlike monolithic architectures, where all components are tightly coupled, microservices allow you to break down an application into smaller, independent services that can be developed, deployed, and scaled independently. Node.js, with its asynchronous, event-driven…
0 notes
Text
Driving Innovation: A Case Study on DevOps Implementation in BFSI Domain
Banking, Financial Services, and Insurance (BFSI), technology plays a pivotal role in driving innovation, efficiency, and customer satisfaction. However, for one BFSI company, the journey toward digital excellence was fraught with challenges in its software development and maintenance processes. With a diverse portfolio of applications and a significant portion outsourced to external vendors, the company grappled with inefficiencies that threatened its operational agility and competitiveness. Identified within this portfolio were 15 core applications deemed critical to the company’s operations, highlighting the urgency for transformative action.
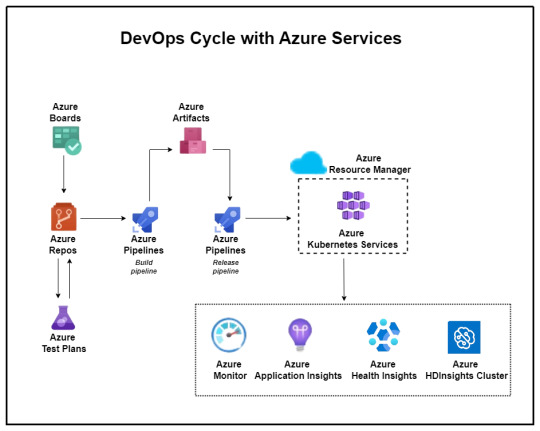
Aspirations for the Future:
Looking ahead, the company envisioned a future state characterized by the establishment of a matured DevSecOps environment. This encompassed several key objectives:
Near-zero Touch Pipeline: Automating product development processes for infrastructure provisioning, application builds, deployments, and configuration changes.
Matured Source-code Management: Implementing robust source-code management processes, complete with review gates, to uphold quality standards.
Defined and Repeatable Release Process: Instituting a standardized release process fortified with quality and security gates to minimize deployment failures and bug leakage.
Modernization: Embracing the latest technological advancements to drive innovation and efficiency.
Common Processes Among Vendors: Establishing standardized processes to enhance understanding and control over the software development lifecycle (SDLC) across different vendors.
Challenges Along the Way:
The path to realizing this vision was beset with challenges, including:
Lack of Source Code Management
Absence of Documentation
Lack of Common Processes
Missing CI/CD and Automated Testing
No Branching and Merging Strategy
Inconsistent Sprint Execution
These challenges collectively hindered the company’s ability to achieve optimal software development, maintenance, and deployment processes. They underscored the critical need for foundational practices such as source code management, documentation, and standardized processes to be addressed comprehensively.
Proposed Solutions:
To overcome these obstacles and pave the way for transformation, the company proposed a phased implementation approach:
Stage 1: Implement Basic DevOps: Commencing with the implementation of fundamental DevOps practices, including source code management and CI/CD processes, for a select group of applications.
Stage 2: Modernization: Progressing towards a more advanced stage involving microservices architecture, test automation, security enhancements, and comprehensive monitoring.
To Expand Your Awareness: https://devopsenabler.com/contact-us
Injecting Security into the SDLC:
Recognizing the paramount importance of security, dedicated measures were introduced to fortify the software development lifecycle. These encompassed:
Security by Design
Secure Coding Practices
Static and Dynamic Application Security Testing (SAST/DAST)
Software Component Analysis
Security Operations
Realizing the Outcomes:
The proposed solution yielded promising outcomes aligned closely with the company’s future aspirations. Leveraging Microsoft Azure’s DevOps capabilities, the company witnessed:
Establishment of common processes and enhanced visibility across different vendors.
Implementation of Azure DevOps for organized version control, sprint planning, and streamlined workflows.
Automation of builds, deployments, and infrastructure provisioning through Azure Pipelines and Automation.
Improved code quality, security, and release management processes.
Transition to microservices architecture and comprehensive monitoring using Azure services.
The BFSI company embarked on a transformative journey towards establishing a matured DevSecOps environment. This journey, marked by challenges and triumphs, underscores the critical importance of innovation and adaptability in today’s rapidly evolving technological landscape. As the company continues to evolve and innovate, the adoption of DevSecOps principles will serve as a cornerstone in driving efficiency, security, and ultimately, the delivery of superior customer experiences in the dynamic realm of BFSI.
Contact Information:
Phone: 080-28473200 / +91 8880 38 18 58
Email: [email protected]
Address: DevOps Enabler & Co, 2nd Floor, F86 Building, ITI Limited, Doorvaninagar, Bangalore 560016.
#BFSI#DevSecOps#software development#maintenance#technology stack#source code management#CI/CD#automated testing#DevOps#microservices#security#Azure DevOps#infrastructure as code#ARM templates#code quality#release management#Kubernetes#testing automation#monitoring#security incident response#project management#agile methodology#software engineering
0 notes
Link
This week's issue contains some of the most interesting articles and news, selected from all the content published in the previous week on the Developers News website. You will read about Comparing The Cloud Leaders, Machine learning with Julia, Testing JavaScript, Gopaddle, Java vs. Python, Bash scripting, Concurrency in Serverless, Kubernetes Deployments, SolidJS , and more
#Gopaddle#SolidJS#devs_news#devs_news_weekly#java#javascript#julia#kubernetes#python#serverless#testing#wasm
0 notes
Text
Intelligence agencies 101: MI6
Dashing spies and deadly agents, from James Bond to Alex Rider and George Smiley. We have all heard of British Intelligence, but just how much do you know about MI6?

1.- It is the oldest secret service in the world.
If we want to get technical, spies have been working for the British crown since 1569, thanks to Queen Elizabeth I and her Secretary of State, Sir Francis Walsingham. But for now, we'll focus on the contemporary Secret Service.
Hear me out, back in 1909 in the midst of what we call the "armed peace", things were getting anything but peaceful. Countries developed and accumulated weapons like it was a sport, and most of them were unsatisfied with the territories they owned. Germany was going all Queen and screaming "I Want It All", which made the rest of the European countries slightly concerned by its imperialistic ambitions.
Britain was the first to grow paranoid and so Prime Minister Asquith decided to have the Committee of Imperial Defence, create a Secret Service Bureau.
However, it is worth mentioning that the existence of the agency wasn't formally acknowledged until 1994, under the Intelligence Services Act, and even though everyone had known about it for ages.
2.- They have very... diverse tasks
Officially, MI6 is tasked with the collection, analysis, and adequate distribution of foreign intelligence (it is a common misconception that MI6 also handles national affairs, that's what its counterpart MI5 is for).
Now, note that I said "officially", and that is because unofficially (it is kind of very illegal), MI6 has been known to carry out espionage activity overseas. But you already knew that, didn't you? Otherwise, why would you be here?
3.- Roles
As described by the SIS itself, there are several roles within the organisation:
Intelligence officers: Must be UK nationals of at least 18, with no drug use and pass a very intrusive security clearance. The jobs are divided into the following subcategories:
Operational Managers: planning and managing intelligence collection operations.
Targeters: turning information (data) into human intelligence operations.
Officers: link to Whitehall (government) as well as validating and testing intelligence.
Case Officers: managing and building relationships with agents.
Operational Data Analysts: Must be UK nationals of at least 18, with no drug use and pass a very intrusive security clearance. Tech abilities are a must. Training course lasts 2 years.
Tech Network Area: Must be UK nationals of at least 18, with no drug use and pass a very intrusive security clearance. Skills in: GoLang, gRPC, Protobuf, Kubernetes & Docker Python, Java, C#, C, C++, and React (+Redux).
Language Specialists: Must be UK nationals of at least 18, with no drug use and pass a very intrusive security clearance. Russian, Arabic and Mandarin linguists are the most solicited, followed by translators.
4.- Their alphabet is a bit jumbled up
Anyone that has ever seen or read any 007 material knows that M is the head of MI6, whether that be Judy Dench, Bernard Lee or Ralph Fiennes.
But what if I told you that the head of MI6 is actually a certain C?
Back when the Secret Service Bureau was created, a 50-year-old Royal Navy officer called Mansfield Cumming (and dubbed "C") was chosen to head the Foreign Section.

5.- MI6 or SIS?
Officially, the agency's current name (adopted in 1920) is Secret Intelligence Service, hence the acronym SIS, but it wasn't always that. We've established that it started its days as the Secret Service Bureau, and during WWI, the agency joined forces with Military Intelligence, even going as far as to adopt the cover name "MI1(c)".
The agency continued to acquire several names throughout the years, such as "Foreign Intelligence Service", "Secret Service", "Special Intelligence Service" and even "C's organisation". It wasn't until WWII started, that the name MI6 was adopted, in reference to the agency being "section six" of Military Intelligence.
And I truly do hate to be the bearer of bad news but... the name MI6, as cool as it sounds, is no longer in use. Writers and journalists still use that name, but those within the organisation just call it SIS nowadays.

6.- They are fond of their traditions
Remember our dear Commander Mansfield? Well, turns out he started a thing. The man used to sign his letters in green ink and always with the letter "C" a tradition that proved to be sticky enough to be passed down to every single Chief afterwards. Another tradition worth mentioning, is that of calling intelligence reports "CX reports", which... you guessed it, is still done to this day.

7.- Special friends
On 1949, the SIS began a formal collaboration with the CIA, even though the agency had already helped to train their predecessor's personnel, the U.S. Office of Strategic Services.
Even the CIA has admitted that the MI6 has provided them with some of the most valuable information of all time, including information that helped during the Cuban Missile Crisis and key elements to the capture of Osama Bin Laden.

I hope this will be of some use to your future writings and do feel free to submit an ask if you happen to have a specific question regarding British intelligence, or any other International Relations subject!
Yours truly,
–The Internationalist
#writing advice#writing help#writing community#writing tips#writing resources#creative writing#james bond#george smiley#alex rider#mi6#spies
445 notes
·
View notes
Text
Top 10 In- Demand Tech Jobs in 2025

Technology is growing faster than ever, and so is the need for skilled professionals in the field. From artificial intelligence to cloud computing, businesses are looking for experts who can keep up with the latest advancements. These tech jobs not only pay well but also offer great career growth and exciting challenges.
In this blog, we’ll look at the top 10 tech jobs that are in high demand today. Whether you’re starting your career or thinking of learning new skills, these jobs can help you plan a bright future in the tech world.
1. AI and Machine Learning Specialists
Artificial Intelligence (AI) and Machine Learning are changing the game by helping machines learn and improve on their own without needing step-by-step instructions. They’re being used in many areas, like chatbots, spotting fraud, and predicting trends.
Key Skills: Python, TensorFlow, PyTorch, data analysis, deep learning, and natural language processing (NLP).
Industries Hiring: Healthcare, finance, retail, and manufacturing.
Career Tip: Keep up with AI and machine learning by working on projects and getting an AI certification. Joining AI hackathons helps you learn and meet others in the field.
2. Data Scientists
Data scientists work with large sets of data to find patterns, trends, and useful insights that help businesses make smart decisions. They play a key role in everything from personalized marketing to predicting health outcomes.
Key Skills: Data visualization, statistical analysis, R, Python, SQL, and data mining.
Industries Hiring: E-commerce, telecommunications, and pharmaceuticals.
Career Tip: Work with real-world data and build a strong portfolio to showcase your skills. Earning certifications in data science tools can help you stand out.
3. Cloud Computing Engineers: These professionals create and manage cloud systems that allow businesses to store data and run apps without needing physical servers, making operations more efficient.
Key Skills: AWS, Azure, Google Cloud Platform (GCP), DevOps, and containerization (Docker, Kubernetes).
Industries Hiring: IT services, startups, and enterprises undergoing digital transformation.
Career Tip: Get certified in cloud platforms like AWS (e.g., AWS Certified Solutions Architect).
4. Cybersecurity Experts
Cybersecurity professionals protect companies from data breaches, malware, and other online threats. As remote work grows, keeping digital information safe is more crucial than ever.
Key Skills: Ethical hacking, penetration testing, risk management, and cybersecurity tools.
Industries Hiring: Banking, IT, and government agencies.
Career Tip: Stay updated on new cybersecurity threats and trends. Certifications like CEH (Certified Ethical Hacker) or CISSP (Certified Information Systems Security Professional) can help you advance in your career.
5. Full-Stack Developers
Full-stack developers are skilled programmers who can work on both the front-end (what users see) and the back-end (server and database) of web applications.
Key Skills: JavaScript, React, Node.js, HTML/CSS, and APIs.
Industries Hiring: Tech startups, e-commerce, and digital media.
Career Tip: Create a strong GitHub profile with projects that highlight your full-stack skills. Learn popular frameworks like React Native to expand into mobile app development.
6. DevOps Engineers
DevOps engineers help make software faster and more reliable by connecting development and operations teams. They streamline the process for quicker deployments.
Key Skills: CI/CD pipelines, automation tools, scripting, and system administration.
Industries Hiring: SaaS companies, cloud service providers, and enterprise IT.
Career Tip: Earn key tools like Jenkins, Ansible, and Kubernetes, and develop scripting skills in languages like Bash or Python. Earning a DevOps certification is a plus and can enhance your expertise in the field.
7. Blockchain Developers
They build secure, transparent, and unchangeable systems. Blockchain is not just for cryptocurrencies; it’s also used in tracking supply chains, managing healthcare records, and even in voting systems.
Key Skills: Solidity, Ethereum, smart contracts, cryptography, and DApp development.
Industries Hiring: Fintech, logistics, and healthcare.
Career Tip: Create and share your own blockchain projects to show your skills. Joining blockchain communities can help you learn more and connect with others in the field.
8. Robotics Engineers
Robotics engineers design, build, and program robots to do tasks faster or safer than humans. Their work is especially important in industries like manufacturing and healthcare.
Key Skills: Programming (C++, Python), robotics process automation (RPA), and mechanical engineering.
Industries Hiring: Automotive, healthcare, and logistics.
Career Tip: Stay updated on new trends like self-driving cars and AI in robotics.
9. Internet of Things (IoT) Specialists
IoT specialists work on systems that connect devices to the internet, allowing them to communicate and be controlled easily. This is crucial for creating smart cities, homes, and industries.
Key Skills: Embedded systems, wireless communication protocols, data analytics, and IoT platforms.
Industries Hiring: Consumer electronics, automotive, and smart city projects.
Career Tip: Create IoT prototypes and learn to use platforms like AWS IoT or Microsoft Azure IoT. Stay updated on 5G technology and edge computing trends.
10. Product Managers
Product managers oversee the development of products, from idea to launch, making sure they are both technically possible and meet market demands. They connect technical teams with business stakeholders.
Key Skills: Agile methodologies, market research, UX design, and project management.
Industries Hiring: Software development, e-commerce, and SaaS companies.
Career Tip: Work on improving your communication and leadership skills. Getting certifications like PMP (Project Management Professional) or CSPO (Certified Scrum Product Owner) can help you advance.
Importance of Upskilling in the Tech Industry
Stay Up-to-Date: Technology changes fast, and learning new skills helps you keep up with the latest trends and tools.
Grow in Your Career: By learning new skills, you open doors to better job opportunities and promotions.
Earn a Higher Salary: The more skills you have, the more valuable you are to employers, which can lead to higher-paying jobs.
Feel More Confident: Learning new things makes you feel more prepared and ready to take on tougher tasks.
Adapt to Changes: Technology keeps evolving, and upskilling helps you stay flexible and ready for any new changes in the industry.
Top Companies Hiring for These Roles
Global Tech Giants: Google, Microsoft, Amazon, and IBM.
Startups: Fintech, health tech, and AI-based startups are often at the forefront of innovation.
Consulting Firms: Companies like Accenture, Deloitte, and PwC increasingly seek tech talent.
In conclusion, the tech world is constantly changing, and staying updated is key to having a successful career. In 2025, jobs in fields like AI, cybersecurity, data science, and software development will be in high demand. By learning the right skills and keeping up with new trends, you can prepare yourself for these exciting roles. Whether you're just starting or looking to improve your skills, the tech industry offers many opportunities for growth and success.
#Top 10 Tech Jobs in 2025#In- Demand Tech Jobs#High paying Tech Jobs#artificial intelligence#datascience#cybersecurity
2 notes
·
View notes
Text
Top Trends in Software Development for 2025
The software development industry is evolving at an unprecedented pace, driven by advancements in technology and the increasing demands of businesses and consumers alike. As we step into 2025, staying ahead of the curve is essential for businesses aiming to remain competitive. Here, we explore the top trends shaping the software development landscape and how they impact businesses. For organizations seeking cutting-edge solutions, partnering with the Best Software Development Company in Vadodara, Gujarat, or India can make all the difference.

1. Artificial Intelligence and Machine Learning Integration:
Artificial Intelligence (AI) and Machine Learning (ML) are no longer optional but integral to modern software development. From predictive analytics to personalized user experiences, AI and ML are driving innovation across industries. In 2025, expect AI-powered tools to streamline development processes, improve testing, and enhance decision-making.
Businesses in Gujarat and beyond are leveraging AI to gain a competitive edge. Collaborating with the Best Software Development Company in Gujarat ensures access to AI-driven solutions tailored to specific industry needs.
2. Low-Code and No-Code Development Platforms:
The demand for faster development cycles has led to the rise of low-code and no-code platforms. These platforms empower non-technical users to create applications through intuitive drag-and-drop interfaces, significantly reducing development time and cost.
For startups and SMEs in Vadodara, partnering with the Best Software Development Company in Vadodara ensures access to these platforms, enabling rapid deployment of business applications without compromising quality.
3. Cloud-Native Development:
Cloud-native technologies, including Kubernetes and microservices, are becoming the backbone of modern applications. By 2025, cloud-native development will dominate, offering scalability, resilience, and faster time-to-market.
The Best Software Development Company in India can help businesses transition to cloud-native architectures, ensuring their applications are future-ready and capable of handling evolving market demands.
4. Edge Computing:
As IoT devices proliferate, edge computing is emerging as a critical trend. Processing data closer to its source reduces latency and enhances real-time decision-making. This trend is particularly significant for industries like healthcare, manufacturing, and retail.
Organizations seeking to leverage edge computing can benefit from the expertise of the Best Software Development Company in Gujarat, which specializes in creating applications optimized for edge environments.
5. Cybersecurity by Design:
With the increasing sophistication of cyber threats, integrating security into the development process has become non-negotiable. Cybersecurity by design ensures that applications are secure from the ground up, reducing vulnerabilities and protecting sensitive data.
The Best Software Development Company in Vadodara prioritizes cybersecurity, providing businesses with robust, secure software solutions that inspire trust among users.
6. Blockchain Beyond Cryptocurrencies:
Blockchain technology is expanding beyond cryptocurrencies into areas like supply chain management, identity verification, and smart contracts. In 2025, blockchain will play a pivotal role in creating transparent, tamper-proof systems.
Partnering with the Best Software Development Company in India enables businesses to harness blockchain technology for innovative applications that drive efficiency and trust.
7. Progressive Web Apps (PWAs):
Progressive Web Apps (PWAs) combine the best features of web and mobile applications, offering seamless experiences across devices. PWAs are cost-effective and provide offline capabilities, making them ideal for businesses targeting diverse audiences.
The Best Software Development Company in Gujarat can develop PWAs tailored to your business needs, ensuring enhanced user engagement and accessibility.
8. Internet of Things (IoT) Expansion:
IoT continues to transform industries by connecting devices and enabling smarter decision-making. From smart homes to industrial IoT, the possibilities are endless. In 2025, IoT solutions will become more sophisticated, integrating AI and edge computing for enhanced functionality.
For businesses in Vadodara and beyond, collaborating with the Best Software Development Company in Vadodara ensures access to innovative IoT solutions that drive growth and efficiency.
9. DevSecOps:
DevSecOps integrates security into the DevOps pipeline, ensuring that security is a shared responsibility throughout the development lifecycle. This approach reduces vulnerabilities and ensures compliance with industry standards.
The Best Software Development Company in India can help implement DevSecOps practices, ensuring that your applications are secure, scalable, and compliant.
10. Sustainability in Software Development:
Sustainability is becoming a priority in software development. Green coding practices, energy-efficient algorithms, and sustainable cloud solutions are gaining traction. By adopting these practices, businesses can reduce their carbon footprint and appeal to environmentally conscious consumers.
Working with the Best Software Development Company in Gujarat ensures access to sustainable software solutions that align with global trends.
11. 5G-Driven Applications:
The rollout of 5G networks is unlocking new possibilities for software development. Ultra-fast connectivity and low latency are enabling applications like augmented reality (AR), virtual reality (VR), and autonomous vehicles.
The Best Software Development Company in Vadodara is at the forefront of leveraging 5G technology to create innovative applications that redefine user experiences.
12. Hyperautomation:
Hyperautomation combines AI, ML, and robotic process automation (RPA) to automate complex business processes. By 2025, hyperautomation will become a key driver of efficiency and cost savings across industries.
Partnering with the Best Software Development Company in India ensures access to hyperautomation solutions that streamline operations and boost productivity.
13. Augmented Reality (AR) and Virtual Reality (VR):
AR and VR technologies are transforming industries like gaming, education, and healthcare. In 2025, these technologies will become more accessible, offering immersive experiences that enhance learning, entertainment, and training.
The Best Software Development Company in Gujarat can help businesses integrate AR and VR into their applications, creating unique and engaging user experiences.
Conclusion:
The software development industry is poised for significant transformation in 2025, driven by trends like AI, cloud-native development, edge computing, and hyperautomation. Staying ahead of these trends requires expertise, innovation, and a commitment to excellence.
For businesses in Vadodara, Gujarat, or anywhere in India, partnering with the Best Software Development Company in Vadodara, Gujarat, or India ensures access to cutting-edge solutions that drive growth and success. By embracing these trends, businesses can unlock new opportunities and remain competitive in an ever-evolving digital landscape.
#Best Software Development Company in Vadodara#Best Software Development Company in Gujarat#Best Software Development Company in India#nividasoftware
3 notes
·
View notes
Text
What are the latest trends in the IT job market?

Introduction
The IT job market is changing quickly. This change is because of new technology, different employer needs, and more remote work.
For jobseekers, understanding these trends is crucial to positioning themselves as strong candidates in a highly competitive landscape.
This blog looks at the current IT job market. It offers insights into job trends and opportunities. You will also find practical strategies to improve your chances of getting your desired role.
Whether you’re in the midst of a job search or considering a career change, this guide will help you navigate the complexities of the job hunting process and secure employment in today’s market.
Section 1: Understanding the Current IT Job Market
Recent Trends in the IT Job Market
The IT sector is booming, with consistent demand for skilled professionals in various domains such as cybersecurity, cloud computing, and data science.
The COVID-19 pandemic accelerated the shift to remote work, further expanding the demand for IT roles that support this transformation.
Employers are increasingly looking for candidates with expertise in AI, machine learning, and DevOps as these technologies drive business innovation.
According to industry reports, job opportunities in IT will continue to grow, with the most substantial demand focused on software development, data analysis, and cloud architecture.
It’s essential for jobseekers to stay updated on these trends to remain competitive and tailor their skills to current market needs.
Recruitment efforts have also become more digitized, with many companies adopting virtual hiring processes and online job fairs.
This creates both challenges and opportunities for job seekers to showcase their talents and secure interviews through online platforms.
NOTE: Visit Now
Remote Work and IT
The surge in remote work opportunities has transformed the job market. Many IT companies now offer fully remote or hybrid roles, which appeal to professionals seeking greater flexibility.
While remote work has increased access to job opportunities, it has also intensified competition, as companies can now hire from a global talent pool.
Section 2: Choosing the Right Keywords for Your IT Resume
Keyword Optimization: Why It Matters
With more employers using Applicant Tracking Systems (ATS) to screen resumes, it’s essential for jobseekers to optimize their resumes with relevant keywords.
These systems scan resumes for specific words related to the job description and only advance the most relevant applications.
To increase the chances of your resume making it through the initial screening, jobseekers must identify and incorporate the right keywords into their resumes.
When searching for jobs in IT, it’s important to tailor your resume for specific job titles and responsibilities. Keywords like “software engineer,” “cloud computing,” “data security,” and “DevOps” can make a huge difference.
By strategically using keywords that reflect your skills, experience, and the job requirements, you enhance your resume’s visibility to hiring managers and recruitment software.
Step-by-Step Keyword Selection Process
Analyze Job Descriptions: Look at several job postings for roles you’re interested in and identify recurring terms.
Incorporate Specific Terms: Include technical terms related to your field (e.g., Python, Kubernetes, cloud infrastructure).
Use Action Verbs: Keywords like “developed,” “designed,” or “implemented” help demonstrate your experience in a tangible way.
Test Your Resume: Use online tools to see how well your resume aligns with specific job postings and make adjustments as necessary.
Section 3: Customizing Your Resume for Each Job Application
Why Customization is Key
One size does not fit all when it comes to resumes, especially in the IT industry. Jobseekers who customize their resumes for each job application are more likely to catch the attention of recruiters. Tailoring your resume allows you to emphasize the specific skills and experiences that align with the job description, making you a stronger candidate. Employers want to see that you’ve taken the time to understand their needs and that your expertise matches what they are looking for.
Key Areas to Customize:
Summary Section: Write a targeted summary that highlights your qualifications and goals in relation to the specific job you’re applying for.
Skills Section: Highlight the most relevant skills for the position, paying close attention to the technical requirements listed in the job posting.
Experience Section: Adjust your work experience descriptions to emphasize the accomplishments and projects that are most relevant to the job.
Education & Certifications: If certain qualifications or certifications are required, make sure they are easy to spot on your resume.
NOTE: Read More
Section 4: Reviewing and Testing Your Optimized Resume
Proofreading for Perfection
Before submitting your resume, it’s critical to review it for accuracy, clarity, and relevance. Spelling mistakes, grammatical errors, or outdated information can reflect poorly on your professionalism.
Additionally, make sure your resume is easy to read and visually organized, with clear headings and bullet points. If possible, ask a peer or mentor in the IT field to review your resume for content accuracy and feedback.
Testing Your Resume with ATS Tools
After making your resume keyword-optimized, test it using online tools that simulate ATS systems. This allows you to see how well your resume aligns with specific job descriptions and identify areas for improvement.
Many tools will give you a match score, showing you how likely your resume is to pass an ATS scan. From here, you can fine-tune your resume to increase its chances of making it to the recruiter’s desk.
Section 5: Trends Shaping the Future of IT Recruitment
Embracing Digital Recruitment
Recruiting has undergone a significant shift towards digital platforms, with job fairs, interviews, and onboarding now frequently taking place online.
This transition means that jobseekers must be comfortable navigating virtual job fairs, remote interviews, and online assessments.
As IT jobs increasingly allow remote work, companies are also using technology-driven recruitment tools like AI for screening candidates.
Jobseekers should also leverage platforms like LinkedIn to increase visibility in the recruitment space. Keeping your LinkedIn profile updated, networking with industry professionals, and engaging in online discussions can all boost your chances of being noticed by recruiters.
Furthermore, participating in virtual job fairs or IT recruitment events provides direct access to recruiters and HR professionals, enhancing your job hunt.
FAQs
1. How important are keywords in IT resumes?
Keywords are essential in IT resumes because they ensure your resume passes through Applicant Tracking Systems (ATS), which scans resumes for specific terms related to the job. Without the right keywords, your resume may not reach a human recruiter.
2. How often should I update my resume?
It’s a good idea to update your resume regularly, especially when you gain new skills or experience. Also, customize it for every job application to ensure it aligns with the job’s specific requirements.
3. What are the most in-demand IT jobs?
Some of the most in-demand IT jobs include software developers, cloud engineers, cybersecurity analysts, data scientists, and DevOps engineers.
4. How can I stand out in the current IT job market?
To stand out, jobseekers should focus on tailoring their resumes, building strong online profiles, networking, and keeping up-to-date with industry trends. Participation in online forums, attending webinars, and earning industry-relevant certifications can also enhance visibility.
Conclusion
The IT job market continues to offer exciting opportunities for jobseekers, driven by technological innovations and changing work patterns.
By staying informed about current trends, customizing your resume, using keywords effectively, and testing your optimized resume, you can improve your job search success.
Whether you are new to the IT field or an experienced professional, leveraging these strategies will help you navigate the competitive landscape and secure a job that aligns with your career goals.
NOTE: Contact Us
2 notes
·
View notes
Text
Navigating the DevOps Landscape: Opportunities and Roles
DevOps has become a game-changer in the quick-moving world of technology. This dynamic process, whose name is a combination of "Development" and "Operations," is revolutionising the way software is created, tested, and deployed. DevOps is a cultural shift that encourages cooperation, automation, and integration between development and IT operations teams, not merely a set of practises. The outcome? greater software delivery speed, dependability, and effectiveness.

In this comprehensive guide, we'll delve into the essence of DevOps, explore the key technologies that underpin its success, and uncover the vast array of job opportunities it offers. Whether you're an aspiring IT professional looking to enter the world of DevOps or an experienced practitioner seeking to enhance your skills, this blog will serve as your roadmap to mastering DevOps. So, let's embark on this enlightening journey into the realm of DevOps.
Key Technologies for DevOps:
Version Control Systems: DevOps teams rely heavily on robust version control systems such as Git and SVN. These systems are instrumental in managing and tracking changes in code and configurations, promoting collaboration and ensuring the integrity of the software development process.
Continuous Integration/Continuous Deployment (CI/CD): The heart of DevOps, CI/CD tools like Jenkins, Travis CI, and CircleCI drive the automation of critical processes. They orchestrate the building, testing, and deployment of code changes, enabling rapid, reliable, and consistent software releases.
Configuration Management: Tools like Ansible, Puppet, and Chef are the architects of automation in the DevOps landscape. They facilitate the automated provisioning and management of infrastructure and application configurations, ensuring consistency and efficiency.
Containerization: Docker and Kubernetes, the cornerstones of containerization, are pivotal in the DevOps toolkit. They empower the creation, deployment, and management of containers that encapsulate applications and their dependencies, simplifying deployment and scaling.
Orchestration: Docker Swarm and Amazon ECS take center stage in orchestrating and managing containerized applications at scale. They provide the control and coordination required to maintain the efficiency and reliability of containerized systems.
Monitoring and Logging: The observability of applications and systems is essential in the DevOps workflow. Monitoring and logging tools like the ELK Stack (Elasticsearch, Logstash, Kibana) and Prometheus are the eyes and ears of DevOps professionals, tracking performance, identifying issues, and optimizing system behavior.
Cloud Computing Platforms: AWS, Azure, and Google Cloud are the foundational pillars of cloud infrastructure in DevOps. They offer the infrastructure and services essential for creating and scaling cloud-based applications, facilitating the agility and flexibility required in modern software development.
Scripting and Coding: Proficiency in scripting languages such as Shell, Python, Ruby, and coding skills are invaluable assets for DevOps professionals. They empower the creation of automation scripts and tools, enabling customization and extensibility in the DevOps pipeline.
Collaboration and Communication Tools: Collaboration tools like Slack and Microsoft Teams enhance the communication and coordination among DevOps team members. They foster efficient collaboration and facilitate the exchange of ideas and information.
Infrastructure as Code (IaC): The concept of Infrastructure as Code, represented by tools like Terraform and AWS CloudFormation, is a pivotal practice in DevOps. It allows the definition and management of infrastructure using code, ensuring consistency and reproducibility, and enabling the rapid provisioning of resources.

Job Opportunities in DevOps:
DevOps Engineer: DevOps engineers are the architects of continuous integration and continuous deployment (CI/CD) pipelines. They meticulously design and maintain these pipelines to automate the deployment process, ensuring the rapid, reliable, and consistent release of software. Their responsibilities extend to optimizing the system's reliability, making them the backbone of seamless software delivery.
Release Manager: Release managers play a pivotal role in orchestrating the software release process. They carefully plan and schedule software releases, coordinating activities between development and IT teams. Their keen oversight ensures the smooth transition of software from development to production, enabling timely and successful releases.
Automation Architect: Automation architects are the visionaries behind the design and development of automation frameworks. These frameworks streamline deployment and monitoring processes, leveraging automation to enhance efficiency and reliability. They are the engineers of innovation, transforming manual tasks into automated wonders.
Cloud Engineer: Cloud engineers are the custodians of cloud infrastructure. They adeptly manage cloud resources, optimizing their performance and ensuring scalability. Their expertise lies in harnessing the power of cloud platforms like AWS, Azure, or Google Cloud to provide robust, flexible, and cost-effective solutions.
Site Reliability Engineer (SRE): SREs are the sentinels of system reliability. They focus on maintaining the system's resilience through efficient practices, continuous monitoring, and rapid incident response. Their vigilance ensures that applications and systems remain stable and performant, even in the face of challenges.
Security Engineer: Security engineers are the guardians of the DevOps pipeline. They integrate security measures seamlessly into the software development process, safeguarding it from potential threats and vulnerabilities. Their role is crucial in an era where security is paramount, ensuring that DevOps practices are fortified against breaches.
As DevOps continues to redefine the landscape of software development and deployment, gaining expertise in its core principles and technologies is a strategic career move. ACTE Technologies offers comprehensive DevOps training programs, led by industry experts who provide invaluable insights, real-world examples, and hands-on guidance. ACTE Technologies's DevOps training covers a wide range of essential concepts, practical exercises, and real-world applications. With a strong focus on certification preparation, ACTE Technologies ensures that you're well-prepared to excel in the world of DevOps. With their guidance, you can gain mastery over DevOps practices, enhance your skill set, and propel your career to new heights.
10 notes
·
View notes
Text
Guide on How to Build Microservices
Microservices are quickly becoming the go-to architectural and organizational strategy for application development. The days of monolithic approaches are behind us as software becomes more complex. Microservices provide greater flexibility and software resilience while creating a push for innovation.
At its core, microservices are about having smaller, independent processes that communicate with one another through a well-designed interface and lightweight API. In this guide, we'll provide a quick breakdown of how to build easy microservices.
Create Your Services
To perform Kubernetes microservices testing, you need to create services. The goal is to have independent containerized services and establish a connection that allows them to communicate.
Keep things simple by developing two web applications. Many developers experimenting with microservices use the iconic "Hello World" test to understand how this architecture works.
Start by building your file structure. You'll need a directory, subdirectories and files to set up the blueprint for your microservices application. The amount of code you'll write for a true microservices application is great. But to keep things simple for experimentation, you can use prewritten codes and directory structures.
The first service you should create is your "hello-world-service." This flask-based application has two endpoints. The first is the welcome page. It includes a button to test the connection to your second service. The second endpoint communicates with your second service.
The second service is the REST-based "welcome service." It delivers a message, allowing you to test that your two services communicate effectively.
The concept is simple: You have one service that you can interact with directly and a second service with the sole function of delivering a message. Using Kubernetes microservices testing, you can force the first service to send a GET request to your REST-based second service.
Containerizing
Before testing, you must make your microservices independent from the hosting environment. To do that, you encapsulate them in Docker containers. You can then set the build path for each service, put them in a running state and start testing.
The result should be a simple web-based application. When you click the "test connection" button, your first service will connect to the second, delivering your "Hello World" message.
Explore the future of scalability – click to harness the power of our Kubernetes platform!
#kubernetes platform#kubernetes preview environments#kubernetes microservices testing#microservice local development environments
0 notes
Text
Ansible Collections: Extending Ansible’s Capabilities
Ansible is a powerful automation tool used for configuration management, application deployment, and task automation. One of the key features that enhances its flexibility and extensibility is the concept of Ansible Collections. In this blog post, we'll explore what Ansible Collections are, how to create and use them, and look at some popular collections and their use cases.
Introduction to Ansible Collections
Ansible Collections are a way to package and distribute Ansible content. This content can include playbooks, roles, modules, plugins, and more. Collections allow users to organize their Ansible content and share it more easily, making it simpler to maintain and reuse.
Key Features of Ansible Collections:
Modularity: Collections break down Ansible content into modular components that can be independently developed, tested, and maintained.
Distribution: Collections can be distributed via Ansible Galaxy or private repositories, enabling easy sharing within teams or the wider Ansible community.
Versioning: Collections support versioning, allowing users to specify and depend on specific versions of a collection. How to Create and Use Collections in Your Projects
Creating and using Ansible Collections involves a few key steps. Here’s a guide to get you started:
1. Setting Up Your Collection
To create a new collection, you can use the ansible-galaxy command-line tool:
ansible-galaxy collection init my_namespace.my_collection
This command sets up a basic directory structure for your collection:
my_namespace/
└── my_collection/
├── docs/
├── plugins/
│ ├── modules/
│ ├── inventory/
│ └── ...
├── roles/
├── playbooks/
├── README.md
└── galaxy.yml
2. Adding Content to Your Collection
Populate your collection with the necessary content. For example, you can add roles, modules, and plugins under the respective directories. Update the galaxy.yml file with metadata about your collection.
3. Building and Publishing Your Collection
Once your collection is ready, you can build it using the following command:
ansible-galaxy collection build
This command creates a tarball of your collection, which you can then publish to Ansible Galaxy or a private repository:
ansible-galaxy collection publish my_namespace-my_collection-1.0.0.tar.gz
4. Using Collections in Your Projects
To use a collection in your Ansible project, specify it in your requirements.yml file:
collections:
- name: my_namespace.my_collection
version: 1.0.0
Then, install the collection using:
ansible-galaxy collection install -r requirements.yml
You can now use the content from the collection in your playbooks:--- - name: Example Playbook hosts: localhost tasks: - name: Use a module from the collection my_namespace.my_collection.my_module: param: value
Popular Collections and Their Use Cases
Here are some popular Ansible Collections and how they can be used:
1. community.general
Description: A collection of modules, plugins, and roles that are not tied to any specific provider or technology.
Use Cases: General-purpose tasks like file manipulation, network configuration, and user management.
2. amazon.aws
Description: Provides modules and plugins for managing AWS resources.
Use Cases: Automating AWS infrastructure, such as EC2 instances, S3 buckets, and RDS databases.
3. ansible.posix
Description: A collection of modules for managing POSIX systems.
Use Cases: Tasks specific to Unix-like systems, such as managing users, groups, and file systems.
4. cisco.ios
Description: Contains modules and plugins for automating Cisco IOS devices.
Use Cases: Network automation for Cisco routers and switches, including configuration management and backup.
5. kubernetes.core
Description: Provides modules for managing Kubernetes resources.
Use Cases: Deploying and managing Kubernetes applications, services, and configurations.
Conclusion
Ansible Collections significantly enhance the modularity, distribution, and reusability of Ansible content. By understanding how to create and use collections, you can streamline your automation workflows and share your work with others more effectively. Explore popular collections to leverage existing solutions and extend Ansible’s capabilities in your projects.
For more details click www.qcsdclabs.com
#redhatcourses#information technology#linux#containerorchestration#container#kubernetes#containersecurity#docker#dockerswarm#aws
2 notes
·
View notes
Text
Journey to Devops
The concept of “DevOps” has been gaining traction in the IT sector for a couple of years. It involves promoting teamwork and interaction, between software developers and IT operations groups to enhance the speed and reliability of software delivery. This strategy has become widely accepted as companies strive to provide software to meet customer needs and maintain an edge, in the industry. In this article we will explore the elements of becoming a DevOps Engineer.
Step 1: Get familiar with the basics of Software Development and IT Operations:
In order to pursue a career as a DevOps Engineer it is crucial to possess a grasp of software development and IT operations. Familiarity with programming languages like Python, Java, Ruby or PHP is essential. Additionally, having knowledge about operating systems, databases and networking is vital.
Step 2: Learn the principles of DevOps:
It is crucial to comprehend and apply the principles of DevOps. Automation, continuous integration, continuous deployment and continuous monitoring are aspects that need to be understood and implemented. It is vital to learn how these principles function and how to carry them out efficiently.
Step 3: Familiarize yourself with the DevOps toolchain:
Git: Git, a distributed version control system is extensively utilized by DevOps teams, for code repository management. It aids in monitoring code alterations facilitating collaboration, among team members and preserving a record of modifications made to the codebase.
Ansible: Ansible is an open source tool used for managing configurations deploying applications and automating tasks. It simplifies infrastructure management. Saves time when performing tasks.
Docker: Docker, on the other hand is a platform for containerization that allows DevOps engineers to bundle applications and dependencies into containers. This ensures consistency and compatibility across environments from development, to production.
Kubernetes: Kubernetes is an open-source container orchestration platform that helps manage and scale containers. It helps automate the deployment, scaling, and management of applications and micro-services.
Jenkins: Jenkins is an open-source automation server that helps automate the process of building, testing, and deploying software. It helps to automate repetitive tasks and improve the speed and efficiency of the software delivery process.
Nagios: Nagios is an open-source monitoring tool that helps us monitor the health and performance of our IT infrastructure. It also helps us to identify and resolve issues in real-time and ensure the high availability and reliability of IT systems as well.
Terraform: Terraform is an infrastructure as code (IAC) tool that helps manage and provision IT infrastructure. It helps us automate the process of provisioning and configuring IT resources and ensures consistency between development and production environments.
Step 4: Gain practical experience:
The best way to gain practical experience is by working on real projects and bootcamps. You can start by contributing to open-source projects or participating in coding challenges and hackathons. You can also attend workshops and online courses to improve your skills.
Step 5: Get certified:
Getting certified in DevOps can help you stand out from the crowd and showcase your expertise to various people. Some of the most popular certifications are:
Certified Kubernetes Administrator (CKA)
AWS Certified DevOps Engineer
Microsoft Certified: Azure DevOps Engineer Expert
AWS Certified Cloud Practitioner
Step 6: Build a strong professional network:
Networking is one of the most important parts of becoming a DevOps Engineer. You can join online communities, attend conferences, join webinars and connect with other professionals in the field. This will help you stay up-to-date with the latest developments and also help you find job opportunities and success.
Conclusion:
You can start your journey towards a successful career in DevOps. The most important thing is to be passionate about your work and continuously learn and improve your skills. With the right skills, experience, and network, you can achieve great success in this field and earn valuable experience.
2 notes
·
View notes
Text
Navigating the DevOps Landscape: A Beginner's Comprehensive
Roadmap In the dynamic realm of software development, the DevOps methodology stands out as a transformative force, fostering collaboration, automation, and continuous enhancement. For newcomers eager to immerse themselves in this revolutionary culture, this all-encompassing guide presents the essential steps to initiate your DevOps expedition.

Grasping the Essence of DevOps Culture: DevOps transcends mere tool usage; it embodies a cultural transformation that prioritizes collaboration and communication between development and operations teams. Begin by comprehending the fundamental principles of collaboration, automation, and continuous improvement.
Immerse Yourself in DevOps Literature: Kickstart your journey by delving into indispensable DevOps literature. "The Phoenix Project" by Gene Kim, Jez Humble, and Kevin Behr, along with "The DevOps Handbook," provides invaluable insights into the theoretical underpinnings and practical implementations of DevOps.
Online Courses and Tutorials: Harness the educational potential of online platforms like Coursera, edX, and Udacity. Seek courses covering pivotal DevOps tools such as Git, Jenkins, Docker, and Kubernetes. These courses will furnish you with a robust comprehension of the tools and processes integral to the DevOps terrain.
Practical Application: While theory is crucial, hands-on experience is paramount. Establish your own development environment and embark on practical projects. Implement version control, construct CI/CD pipelines, and deploy applications to acquire firsthand experience in applying DevOps principles.

Explore the Realm of Configuration Management: Configuration management is a pivotal facet of DevOps. Familiarize yourself with tools like Ansible, Puppet, or Chef, which automate infrastructure provisioning and configuration, ensuring uniformity across diverse environments.
Containerization and Orchestration: Delve into the universe of containerization with Docker and orchestration with Kubernetes. Containers provide uniformity across diverse environments, while orchestration tools automate the deployment, scaling, and management of containerized applications.
Continuous Integration and Continuous Deployment (CI/CD): Integral to DevOps is CI/CD. Gain proficiency in Jenkins, Travis CI, or GitLab CI to automate code change testing and deployment. These tools enhance the speed and reliability of the release cycle, a central objective in DevOps methodologies.
Grasp Networking and Security Fundamentals: Expand your knowledge to encompass networking and security basics relevant to DevOps. Comprehend how security integrates into the DevOps pipeline, embracing the principles of DevSecOps. Gain insights into infrastructure security and secure coding practices to ensure robust DevOps implementations.
Embarking on a DevOps expedition demands a comprehensive strategy that amalgamates theoretical understanding with hands-on experience. By grasping the cultural shift, exploring key literature, and mastering essential tools, you are well-positioned to evolve into a proficient DevOps practitioner, contributing to the triumph of contemporary software development.
2 notes
·
View notes
Text
Full Stack Development: Using DevOps and Agile Practices for Success
In today’s fast-paced and highly competitive tech industry, the demand for Full Stack Developers is steadily on the rise. These versatile professionals possess a unique blend of skills that enable them to handle both the front-end and back-end aspects of software development. However, to excel in this role and meet the ever-evolving demands of modern software development, Full Stack Developers are increasingly turning to DevOps and Agile practices. In this comprehensive guide, we will explore how the combination of Full Stack Development with DevOps and Agile methodologies can lead to unparalleled success in the world of software development.

Full Stack Development: A Brief Overview
Full Stack Development refers to the practice of working on all aspects of a software application, from the user interface (UI) and user experience (UX) on the front end to server-side scripting, databases, and infrastructure on the back end. It requires a broad skill set and the ability to handle various technologies and programming languages.
The Significance of DevOps and Agile Practices
The environment for software development has changed significantly in recent years. The adoption of DevOps and Agile practices has become a cornerstone of modern software development. DevOps focuses on automating and streamlining the development and deployment processes, while Agile methodologies promote collaboration, flexibility, and iterative development. Together, they offer a powerful approach to software development that enhances efficiency, quality, and project success. In this blog, we will delve into the following key areas:
Understanding Full Stack Development
Defining Full Stack Development
We will start by defining Full Stack Development and elucidating its pivotal role in creating end-to-end solutions. Full Stack Developers are akin to the Swiss Army knives of the development world, capable of handling every aspect of a project.
Key Responsibilities of a Full Stack Developer
We will explore the multifaceted responsibilities of Full Stack Developers, from designing user interfaces to managing databases and everything in between. Understanding these responsibilities is crucial to grasping the challenges they face.
DevOps’s Importance in Full Stack Development
Unpacking DevOps
A collection of principles known as DevOps aims to eliminate the divide between development and operations teams. We will delve into what DevOps entails and why it matters in Full Stack Development. The benefits of embracing DevOps principles will also be discussed.
Agile Methodologies in Full Stack Development
Introducing Agile Methodologies
Agile methodologies like Scrum and Kanban have gained immense popularity due to their effectiveness in fostering collaboration and adaptability. We will introduce these methodologies and explain how they enhance project management and teamwork in Full Stack Development.

Synergy Between DevOps and Agile
The Power of Collaboration
We will highlight how DevOps and Agile practices complement each other, creating a synergy that streamlines the entire development process. By aligning development, testing, and deployment, this synergy results in faster delivery and higher-quality software.
Tools and Technologies for DevOps in Full Stack Development
Essential DevOps Tools
DevOps relies on a suite of tools and technologies, such as Jenkins, Docker, and Kubernetes, to automate and manage various aspects of the development pipeline. We will provide an overview of these tools and explain how they can be harnessed in Full Stack Development projects.

Implementing Agile in Full Stack Projects
Agile Implementation Strategies
We will delve into practical strategies for implementing Agile methodologies in Full Stack projects. Topics will include sprint planning, backlog management, and conducting effective stand-up meetings.
Best Practices for Agile Integration
We will share best practices for incorporating Agile principles into Full Stack Development, ensuring that projects are nimble, adaptable, and responsive to changing requirements.
Learning Resources and Real-World Examples
To gain a deeper understanding, ACTE Institute present case studies and real-world examples of successful Full Stack Development projects that leveraged DevOps and Agile practices. These stories will offer valuable insights into best practices and lessons learned. Consider enrolling in accredited full stack developer training course to increase your full stack proficiency.
Challenges and Solutions
Addressing Common Challenges
No journey is without its obstacles, and Full Stack Developers using DevOps and Agile practices may encounter challenges. We will identify these common roadblocks and provide practical solutions and tips for overcoming them.
Benefits and Outcomes
The Fruits of Collaboration
In this section, we will discuss the tangible benefits and outcomes of integrating DevOps and Agile practices in Full Stack projects. Faster development cycles, improved product quality, and enhanced customer satisfaction are among the rewards.
In conclusion, this blog has explored the dynamic world of Full Stack Development and the pivotal role that DevOps and Agile practices play in achieving success in this field. Full Stack Developers are at the forefront of innovation, and by embracing these methodologies, they can enhance their efficiency, drive project success, and stay ahead in the ever-evolving tech landscape. We emphasize the importance of continuous learning and adaptation, as the tech industry continually evolves. DevOps and Agile practices provide a foundation for success, and we encourage readers to explore further resources, courses, and communities to foster their growth as Full Stack Developers. By doing so, they can contribute to the development of cutting-edge solutions and make a lasting impact in the world of software development.
#web development#full stack developer#devops#agile#education#information#technology#full stack web development#innovation
2 notes
·
View notes
Text
AEM aaCS aka Adobe Experience Manager as a Cloud Service
As the industry standard for digital experience management, Adobe Experience Manager is now being improved upon. Finally, Adobe is transferring Adobe Experience Manager (AEM), its final on-premises product, to the cloud.
AEM aaCS is a modern, cloud-native application that accelerates the delivery of omnichannel application.
The AEM Cloud Service introduces the next generation of the AEM product line, moving away from versioned releases like AEM 6.4, AEM 6.5, etc. to a continuous release with less versioning called "AEM as a Cloud Service."
AEM Cloud Service adopts all benefits of modern cloud based services:
Availability
The ability for all services to be always on, ensuring that our clients do not suffer any downtime, is one of the major advantages of switching to AEM Cloud Service. In the past, there was a requirement to regularly halt the service for various maintenance operations, including updates, patches, upgrades, and certain standard maintenance activities, notably on the author side.
Scalability
The AEM Cloud Service's instances are all generated with the same default size. AEM Cloud Service is built on an orchestration engine (Kubernetes) that dynamically scales up and down in accordance with the demands of our clients without requiring their involvement. both horizontally and vertically. Based on, scaling can be done manually or automatically.
Updated Code Base
This might be the most beneficial and much anticipated function that AEM Cloud Service offers to consumers. With the AEM Cloud Service, Adobe will handle upgrading all instances to the most recent code base. No downtime will be experienced throughout the update process.
Self Evolving
Continually improving and learning from the projects our clients deploy, AEM Cloud Service. We regularly examine and validate content, code, and settings against best practices to help our clients understand how to accomplish their business objectives. AEM cloud solution components that include health checks enable them to self-heal.
AEM as a Cloud Service: Changes and Challenges
When you begin your work, you will notice a lot of changes in the aem cloud jar. Here are a few significant changes that might have an effect on how we now operate with aem:-
1)The significant exhibition bottleneck that the greater part of huge endeavor DAM clients are confronting is mass transferring of resource on creator example and afterward DAM Update work process debase execution of entire creator occurrence. To determine this AEM Cloud administration brings Resource Microservices for serverless resource handling controlled by Adobe I/O. Presently when creator transfers any resource it will go straightforwardly to cloud paired capacity then adobe I/O is set off which will deal with additional handling by utilizing versions and different properties that has been designed.
2)Due to Adobe's complete management of AEM cloud service, developers and operations personnel may not be able to directly access logs. As of right now, the only way I know of to request access, error, dispatcher, and other logs will be via a cloud manager download link.
3)The only way for AEM Leads to deploy is through cloud manager, which is subject to stringent CI/CD pipeline quality checks. At this point, you should concentrate on test-driven development with greater than 50% test coverage. Go to https://docs.adobe.com/content/help/en/experience-manager-cloud-manager/using/how-to-use/understand-your-test-results.html for additional information.
4)AEM as a cloud service does not currently support AEM screens or AEM Adaptive forms.
5)Continuous updates will be pushed to the cloud-based AEM Base line image to support version-less solutions. Consequently, any Asset UI console or libs granite customizations: Up until AEM 6.5, the internal node, which could be used as a workaround to meet customer requirements, is no longer possible because it will be replaced with each base line image update.
6)Local sonar cannot use the code quality rules that are available in cloud manager before pushing to git. which I believe will result in increased development time and git commits. Once the development code is pushed to the git repository and the build is started, cloud manager will run sonar checks and tell you what's wrong. As a precaution, I recommend that you do not have any problems with the default rules in your local environment and that you continue to update the rules whenever you encounter them while pushing the code to cloud git.
AEM Cloud Service Does Not Support These Features
1.AEM Sites Commerce add-on 2.Screens add-on 3.Networks add-on 4.AEM Structures 5.Admittance to Exemplary UI. 6.Page Editor is in Developer Mode. 7./apps or /libs are ready-only in dev/stage/prod environment – changes need to come in via CI/CD pipeline that builds the code from the GIT repo. 8.OSGI bundles and settings: the dev, stage, and production environments do not support the web console.
If you encounter any difficulties or observe any issue , please let me know. It will be useful for AEM people group.
3 notes
·
View notes